神经网络
神经网络
nodaoliUV 安装GPU PyTorch
1 | torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 |
1 | dependencies = [ |
简单使用
1 | uv pip install numpy torch torchvision matplotlib --torch-backend=auto |
激活函数
没有激活函数,那么不管堆多少层,本质都是“线性模型”
就是经过这一个函数f(x)=wx+b,w是斜率也是权重,b就是偏置
权重的数量个数值都是PyTorch自动设置的
当一个特征比较重要,它的权重就会比较高
[!note]-
假设我们要设计一个简单的神经元,判断“今天是否去跑步”。
• 输入 :天气好不好(1 好,0 差)
• 输入 :是否有空(1 有,0 无)
你的设计(参数设定):
• 设定权重 ,(说明天气对你的决定影响更大)。
• 设定偏置 (这代表你天生有点懒,需要足够的正面刺激才会出门)。
场景 1:天气好(1),但没空(0)
- $z = (5 \times 1) + (2 \times 0) + (-3) = 2$
- 结论:有 88% 的概率会去跑步。
场景 2:天气差(0),有空(1)- $z = (5 \times 0) + (2 \times 1) + (-3) = -1$
- 结论:只有 27% 的概率会去跑步。
层
权重:是多少个输入参数,有PyTorch框架决定,具体的数值是多少也是由框架自动计算。
例如一个识别手写数字
1 | 784 - 128 -10 |
第一层隐藏层,如果是32欠拟合,256过拟合
然后可不止一层,可以多加几层
没有正确答案,只有“是否合适”
总结
其实就是设计好架构以及给出数据集,然后让初始函数训练成一个多层复合函数(成品超小模型)
当使用训练出来的这个多层复合函数的时候,就是把要被识别Content经过多层复合函数,最终得出特征的比值权重
例如识别手写数字,如果最终的结果5的权重比较高,识别出来的结果就是5
细分
nn.Linear(in_features, out_features, bias=True)
输入向量维度,输出向量维度,是否使用偏置项
1 | self.custom_name = nn.Linear(784,128) |
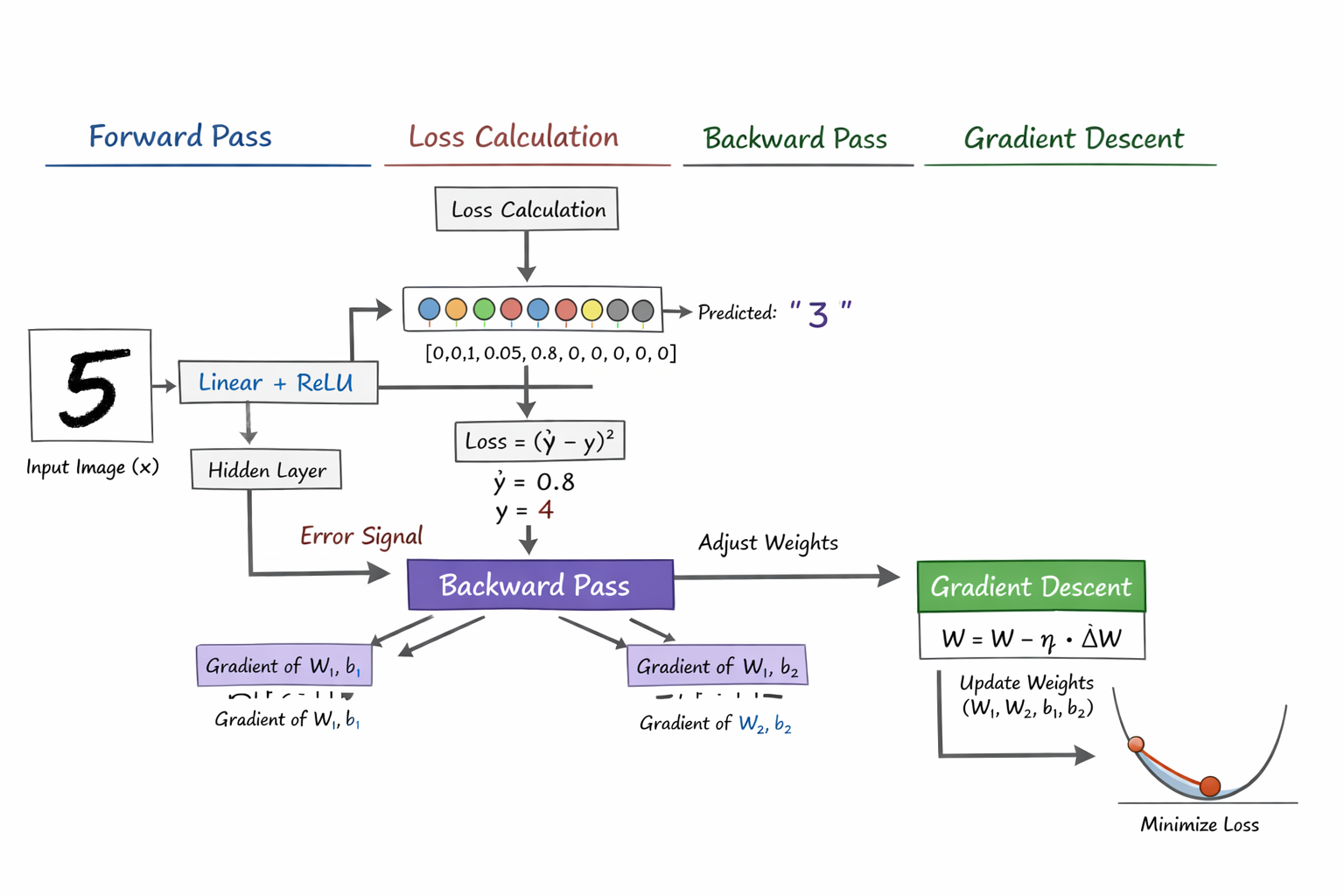
前向传播
训练和推理
1 | 训练时 |
| 项目 | 向前传播 | 反向传播 |
|---|---|---|
| 方向 | 输入->输出 | 输出->输入 |
| 做什么 | 计算结果 | 计算梯度 |
| 改参数 | 不改 | 本身不改 |
| 依赖 | 当前参数 | loss |
| “按照菜谱做一遍,看看味道如何”-“分析哪里太咸,盐该少放多少” |
损失函数
计算预算的结果与正确结果之间的差距有多大,错的有多离谱
计算出梯度
1 | Loss(y_true, y_pred) |
梯度
就是一个导函数,当导函数是正,说明向上,那也就是说明正儿损失函数增大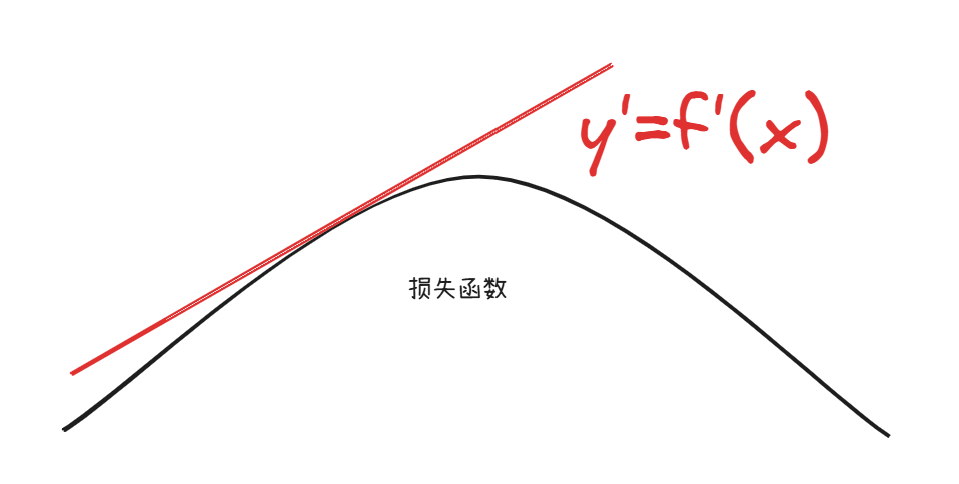
新权重=旧权重−学习率×梯度
GPT



评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果

